

GA4では探索においてセッション セグメントを作成することができるが、現時点ではまだLooker Studioにはセグメントの機能は備わっておらず、この点においてもLooker StudioとGA4をAPI接続で利用することの大きな制約の1つとなっている。しかし、BigQueryを活用することでセグメント機能を再現することができるため、Looker Studioの利用ではBigQueryの活用をマストにすることを推奨する。
セッション セグメントとは
GA4のセッションは30分間Webサイトの操作がなければセッションが切れ、Webサイトの何かしらの操作があればセッションが永続的に継続される(デフォルトのセッションのタイムアウト時間は30分間であるが調整可能)。ただ、通常何時間にも渡り訪問したサイトを閲覧し続けるということはあり得ないので、どこかのタイミングでセッションが切れることになる。そのため、一般的にはセッションの継続時間は十数秒から長くて数分となる。さらに補足説明するとサイトを離脱し、30分間経たずに再訪問した場合はセッションは切り替わらない。また、30分以内にサイトへの流入元が変わっても同一のセッションとなる。要はセッションとは1回の訪問におけるユーザー行動を見るためのものといってよい。
参考:[GA4] アナリティクスのセッションについて -アナリティクス ヘルプ
そもそもセグメントとは?
セグメントを適用させるとは、何かしらの属性に基づく全体の中の一部に限定させるということになる。その属性に一致させるための結合条件として、セッションベースであればセッションIDで紐付けを行う。例えば、「新規ユーザー」セグメントであれば、「新規ユーザー」セグメントを探索で作成し適用させることで、新規ユーザーに限定されたデータを可視化することが可能になる。BigQueryにおいても同様で、セッションベースのセグメントであれば、初めに作成したいセグメント条件を満たすセッションIDを抽出し、そのセッションIDを絞り込みたいデータに結合することでセッションセグメントを適用させることができる。
特定のイベントに基づくセッションセグメントを作成するクエリ
例えば特定のコンバージョンアクションを達成したセッションセグメントを作成するには、対象となるイベント名で条件を絞込み、重複のないセッションIDを集計する。ここでは、すでに’event_name’で対象となるコンバージョンを指定できることを前提としている。
WITH
SEG_ssid AS (
SELECT
CONCAT(user_pseudo_id, '-', CAST(ga_session_id AS STRING)) AS ssid
FROM (
SELECT
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20240401' AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND (
event_name = 'purchase_A'
OR
event_name = 'purchase_B'
)
)
GROUP BY
ssid
)
SELECT
*
FROM
SEG_ssidセッションセグメントをWHERE句でセッションID同士で結合
WHERE
event_data.ssid IN (SELECT ssid FROM SEG_ssid)重複のないセッションIDを集計することができたら、それをセグメントを適用させたいセッションIDと紐づけを行う。そのためには、このWHERE条件のようにセグメントを適用させたいセッションIDが、セグメントのセッションIDにIN(含まれているか)を判定する結合条件によりセグメントを適用させる。
CVを達成したユーザーが閲覧したページを集計するクエリ
先ほど作成したセグメントを適用することで、例えばコンバージョンを達成したユーザーが閲覧したページを集計することが可能になる。ここでは、セッションセグメントとして適用させるので、CVを達成した際の訪問時にアクセスしたページということになる。
WITH
SEG_ssid AS (
SELECT
CONCAT(user_pseudo_id, '-', CAST(ga_session_id AS STRING)) AS ssid
FROM (
SELECT
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20240401' AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND (
event_name = 'purchase_A'
OR
event_name = 'purchase_B'
)
)
GROUP BY
ssid
),
Pagelocation_PV AS (
SELECT
ymd,
page_location,
COUNT(*) AS _pv
FROM (
SELECT
PARSE_DATE("%Y%m%d", event_date) AS ymd,
REGEXP_REPLACE((SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r"\?.*", "") AS page_location,
CONCAT(user_pseudo_id, '-', CAST((SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS STRING)) AS ssid
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20240401' AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND
event_name = 'page_view'
) AS event_data
WHERE
event_data.ssid IN (SELECT ssid FROM SEG_ssid)
GROUP BY
ymd,
page_location
ORDER BY
ymd ASC,
_pv DESC
)
SELECT
*
FROM
Pagelocation_PVChatGPTによるクエリ解説
1. SEG_ssid CTE(共通テーブル式)
このCTE(Common Table Expression)は、特定の購買イベントをトリガーしたユーザーセッションの一意のセッションID(ssid)を生成しています。・データ抽出: user_pseudo_id(ユーザーの疑似ID)と ga_session_id(Google Analyticsによって割り当てられたセッションID)を結合し、一意のセッションID(ssid)を形成します。
・フィルタリング: event_name が purchase_A または purchase_B のいずれかに該当するレコードを抽出します。これにより、これらの購買イベントに関与したセッションのみが対象になります。
・期間指定: _TABLE_SUFFIX は指定された期間(2024年4月1日から現在日までの前日まで)にフィルタリングしています。2. Pagelocation_PV CTE
このCTEでは、特定のセッションがどのページを訪れたか、及び各ページのページビュー数を集計します。・ページビューのデータ取得: event_name が page_view のレコードからページのURLを抽出し、クエリパラメータを除去してページの基本URL(page_location)を取得します。
・データフィルタリング: event_data.ssid が SEG_ssid で抽出された ssid に含まれているものだけを抽出しています。これにより、購買イベントをトリガーしたセッションがどのページを訪れたかが明確になります。
・ページビュー数の集計: 各ページごとにページビュー数(_pv)を集計し、日付(ymd)とページURL(page_location)でグループ化しています。
・ソート: 結果は日付(ymd)とページビュー数(_pv)の降順でソートされ、ページの人気度が高い順に表示されます。最終SELECT文
最終的に、Pagelocation_PV CTEからすべてのデータを選択し、購買イベントをトリガーしたセッションにおけるページごとのビュー数を表示します。これにより、特定の購買行動を行ったユーザーがどのページに興味を持ったかが分かります。
より明示的な結合条件によるセグメントを適用させるクエリ
WITH
SEG_ssid AS (
SELECT
CONCAT(user_pseudo_id, '-', CAST(ga_session_id AS STRING)) AS ssid
FROM (
SELECT
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20240401' AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND (
event_name = 'purchase_A'
OR
event_name = 'purchase_B'
)
)
GROUP BY
ssid
),
Pagelocation_PV AS (
SELECT
ymd,
page_location,
COUNT(*) AS _pv
FROM (
SELECT
PARSE_DATE("%Y%m%d", event_date) AS ymd,
REGEXP_REPLACE((SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r"\?.*", "") AS page_location,
CONCAT(user_pseudo_id, '-', CAST((SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS STRING)) AS ssid
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20240401' AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND
event_name = 'page_view'
) AS e
INNER JOIN
SEG_ssid AS s
ON
e.ssid = s.ssid
GROUP BY
ymd,
page_location
ORDER BY
ymd ASC,
_pv DESC
)
SELECT
*
FROM
Pagelocation_PVINとINNER JOINはどちらが適切か? ChatGPTによる解説
`event_data.ssid IN (SELECT ssid FROM SEG_ssid)` という条件を使用するのと、`INNER JOIN`を使った結合は、両者ともにデータを結合するための効率的な方法ですが、使用状況によって最適な選択が異なります。
### `event_data.ssid IN (SELECT ssid FROM SEG_ssid)` を使用する場合
この方法は、サブクエリを使って特定のセッションID (`ssid`) がセグメントに含まれているかをチェックします。SQLエンジンがこのサブクエリをどのように処理するかによっては、特に`SEG_ssid`が大きい場合にパフォーマンスが低下する可能性があります。サブクエリが一度に多くのデータを返すと、全体のパフォーマンスに影響を与えることがあります。### `INNER JOIN`を使った結合を使用する場合
`INNER JOIN`を使用する方法は、`event_data`と`SEG_ssid`テーブルを`ssid`で直接結合します。この方法は、一般的に`IN`句を使用するよりも効率的です。`JOIN`はデータベースが最適化しやすく、大量のデータに対してより効率的に動作することが多いため、特に大規模なデータセットでの処理に適しています。### どちらが適切か
– **パフォーマンス**: `INNER JOIN`は通常、`IN`句を使うよりもパフォーマンスが良いです。データベースが効率的にインデックスを活用できるため、特に`SEG_ssid`が大きい場合に推奨されます。
– **可読性**: `IN`句を使った条件は、SQLが比較的シンプルで読みやすい場合がありますが、パフォーマンスが重要な場面では`INNER JOIN`の方が優れています。したがって、パフォーマンスと効率を重視するならば、`INNER JOIN`を使用することをお勧めします。特に、大規模なデータセットで作業している場合や、クエリの実行速度が重要な場合は、`INNER JOIN`が一般的に優れた選択となります。ーしたセッションにおけるページごとのビュー数を表示します。これにより、特定の購買行動を行ったユーザーがその後どのページに興味を持ったかが分かります。
HAVING句でも置き換えられるが非推奨
以上の結果を得るためには他の方法でクエリを書くことも可能であり、HAVING句を使うことも可能ではあるが、あまりよい方法だとはいえない。HAVING句を使うためには、データを集約する必要があるため、すでに集約済みであってもMIN関数などでフィールドを括る必要が出てくる。また、より早い段階でデータを絞り込めるのであれば、最初にWHERE句で絞り込んでしまった方が余計なクエリ処理を走らせる必要もなくなるのでコストの削減にもつながる。
ChatGPTによるHAVING句とWHERE句による比較
HAVING句を使う方法は、SQLクエリの中で特定の条件を満たす集約結果のみをフィルタリングする場合に適しています。ただし、HAVING句の使用は通常、集約関数の結果に基づくフィルタリングに限られます。提供された例では、HAVING句を使用して非集約条件でフィルタリングしていますが、これは通常のWHERE句の使用に置き換えることができ、より直感的で効率的な場合が多いです。
提供されたクエリでは、HAVING句を使ってuser_pseudo_idがcv_usersサブクエリに含まれるものだけを取得しています。この処理は、代わりにサブクエリを内部結合(INNER JOIN)で使用することで同じ結果を得ることができます。INNER JOINを使用すると、SQLエンジンは通常、より効率的にデータをフィルタリングできるため、特に大規模なデータセットではパフォーマンスの向上が見込まれます。
セッションセグメントを適用させたサンプルクエリ集
CVを達成したユーザーのページ別訪問数を集計するクエリ
参考としてページビューではなく、ページ別訪問数を集計するクエリ例を記載する。つまり、ページごとのセッション数をカウントすることで、何回もページを閲覧したことによる重複カウントを省いた集計を重視する場合にページ別訪問数を採用する。
WITH
SEG_ssid AS (
SELECT
CONCAT(user_pseudo_id, '-', CAST(ga_session_id AS STRING)) AS ssid
FROM (
SELECT
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20240401' AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND (
event_name = 'purchase_A'
OR
event_name = 'purchase_B'
)
)
GROUP BY
ssid
),
DailyPageSession AS (
SELECT
ymd,
page_location,
COUNT(DISTINCT ssid) AS _ssuu
FROM (
SELECT
ymd,
page_location,
ssid
FROM (
SELECT
ymd,
page_location,
CONCAT(user_pseudo_id, '-', CAST(ga_session_id AS STRING)) AS ssid
FROM (
SELECT
PARSE_DATE("%Y%m%d", event_date) AS ymd,
REGEXP_REPLACE((SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r"\?.*", "") AS page_location,
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN '20240401' AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(),INTERVAL 1 DAY))
)
) AS event_data
WHERE
event_data.ssid IN (SELECT ssid FROM SEG_ssid)
)
GROUP BY
ymd,
page_location
ORDER BY
ymd ASC,
_ssuu DESC
)
SELECT
*
FROM
DailyPageSessionページA・Bを閲覧した日次セッション数を集計
CREATE TEMP FUNCTION date_from() RETURNS STRING AS ('20240401');
WITH
SEG_pageAB AS (
SELECT
CONCAT(user_pseudo_id, '-', CAST(ga_session_id AS STRING)) AS ssid
FROM(
SELECT
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id,
REGEXP_REPLACE((SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r"\?.*", "") AS page_location
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN date_from() AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND
event_name = 'page_view'
)
WHERE
page_location = 'Page_A'
GROUP BY
ssid
INTERSECT DISTINCT
SELECT
CONCAT(user_pseudo_id, '-', CAST(ga_session_id AS STRING)) AS ssid
FROM(
SELECT
user_pseudo_id,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id,
REGEXP_REPLACE((SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'), r"\?.*", "") AS page_location
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN date_from() AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND
event_name = 'page_view'
)
WHERE
page_location = 'page_B'
GROUP BY
ssid
),
PageAB_SSUU AS (
SELECT
ymd,
COUNT(DISTINCT ssid) AS _ssuu
FROM (
SELECT
PARSE_DATE("%Y%m%d", event_date) AS ymd,
CONCAT(user_pseudo_id, '-', CAST((SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS STRING)) AS ssid
FROM
`<project>.<dataset>.events_*`
WHERE
_TABLE_SUFFIX BETWEEN date_from() AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
AND
event_name = 'page_view'
) AS event_data
WHERE
event_data.ssid IN (SELECT ssid FROM SEG_pageAB)
GROUP BY
ymd
ORDER BY
ymd ASC
)
SELECT
*
FROM
PageAB_SSUU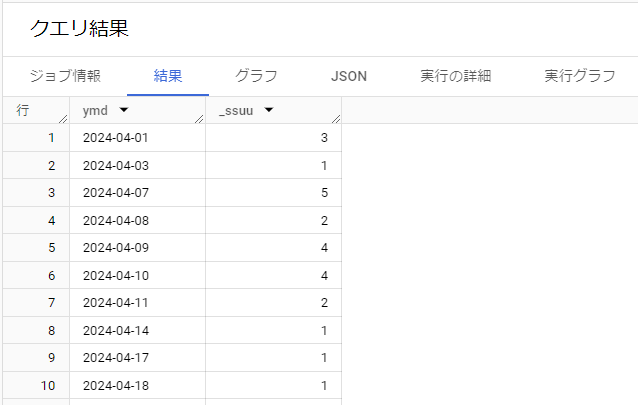
ChatGPTによるクエリ解説
このクエリは、特定の2つのページ(Page_AとPage_B)を両方とも訪問したセッション(セッションセグメント)を特定し、そのセグメントのセッションが日ごとにどれだけ存在するかを集計しています。以下は段階的な解説です:
### 1. TEMP FUNCTIONの定義
– `date_from()`という一時関数が定義されており、特定の日付(ここでは2024年4月1日)を返します。これはクエリで使用される日付の範囲を指定するために使われます。### 2. セッションセグメントの作成 (SEG_pageAB)
– このCommon Table Expression(CTE)では、ユーザーID (`user_pseudo_id`) とセッションID (`ga_session_id`) を組み合わせて、ユニークなセッション識別子 (`ssid`) を作成します。
– それぞれのレコードについて、ページのURLをクエリパラメーターである ‘?’ 以降を除去してクリーンなURLを抽出します。
– この処理は、2つのページ(Page_A と Page_B)について個別に行われ、それぞれのページを訪れたセッションを判定します。
– 最終的に、これら2つのページを両方訪れたセッションのみを特定するために `INTERSECT DISTINCT` を使用しています。これにより、Page_AとPage_Bの両方を訪問したセッションのみが残ります。### 3. ページビューの日次集計 (PageAB_SSUU)
– このCTEでは、全ページビューイベントからセッション識別子と日付を抽出し、`SEG_pageAB`で識別されたセグメントに含まれるセッションのみをフィルタリングします。
– `WHERE`句で、抽出されたセッション識別子が`SEG_pageAB`で得られたセッションセグメントに含まれるかをチェックします。
– 最後に、日付 (`ymd`) ごとにユニークなセッションIDの数をカウントしています。これにより、各日にそのセグメントに該当するユーザーが何人いたかがわかります。### 4. 結果の選択
– 最終的なSELECT文で、`PageAB_SSUU`から得られた結果を選択しています。これにより、日付ごとのユニークなセッション数が表示されます。このクエリは、特定のユーザー行動(2つのページの訪問)に基づくセッションセグメントの行動を時間的に解析するのに有効です。
‘first_visit’が付いた訪問日の全てのセッションを新規セッションとするセグメント

GA4の分析において新規とリピーターを分けて分析したいケースがよくある。GA4の新規ユーザーの定義では初回訪問は新規ユーザーとしてカウントされるが、その日の2回目以降のセッションではリピーターとしてカウントされてしまう。
 『Googleアナリティクス4 完全入門』 書籍販売中!
『Googleアナリティクス4 完全入門』 書籍販売中!


















{kind=link}